Do-It-Yourself#
import pandas, geopandas, contextily
/tmp/ipykernel_13356/1400290490.py:1: UserWarning: Shapely 2.0 is installed, but because PyGEOS is also installed, GeoPandas will still use PyGEOS by default for now. To force to use and test Shapely 2.0, you have to set the environment variable USE_PYGEOS=0. You can do this before starting the Python process, or in your code before importing geopandas:
import os
os.environ['USE_PYGEOS'] = '0'
import geopandas
In a future release, GeoPandas will switch to using Shapely by default. If you are using PyGEOS directly (calling PyGEOS functions on geometries from GeoPandas), this will then stop working and you are encouraged to migrate from PyGEOS to Shapely 2.0 (https://shapely.readthedocs.io/en/latest/migration_pygeos.html).
import pandas, geopandas, contextily
Task I: AirBnb distribution in Beijing#
In this task, you will explore patterns in the distribution of the location of AirBnb properties in Beijing. For that, we will use data from the same provider as we did for the clustering block: Inside AirBnb. We are going to read in a file with the locations of the properties available as of August 15th. 2019:
url = (
"http://data.insideairbnb.com/china/beijing/beijing/"
"2023-03-29/data/listings.csv.gz"
)
url
'http://data.insideairbnb.com/china/beijing/beijing/2023-03-29/data/listings.csv.gz'
abb = pandas.read_csv(url)
Alternative
Instead of reading the file directly off the web, it is possible to download it manually, store it on your computer, and read it locally. To do that, you can follow these steps:
Download the file by right-clicking on this link and saving the file
Place the file on the same folder as the notebook where you intend to read it
Replace the code in the cell above by:
abb = pandas.read_csv("listings.csv")
Note the code cell above requires internet connectivity. If you are not online but have a full copy of the GDS course in your computer (downloaded as suggested in the infrastructure page), you can read the data with the following line of code:
abb = pandas.read_csv("../data/web_cache/abb_listings.csv.zip")
This gives us a table with the following information:
abb.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 21448 entries, 0 to 21447
Data columns (total 16 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 21448 non-null int64
1 name 21448 non-null object
2 host_id 21448 non-null int64
3 host_name 21428 non-null object
4 neighbourhood_group 0 non-null float64
5 neighbourhood 21448 non-null object
6 latitude 21448 non-null float64
7 longitude 21448 non-null float64
8 room_type 21448 non-null object
9 price 21448 non-null int64
10 minimum_nights 21448 non-null int64
11 number_of_reviews 21448 non-null int64
12 last_review 12394 non-null object
13 reviews_per_month 12394 non-null float64
14 calculated_host_listings_count 21448 non-null int64
15 availability_365 21448 non-null int64
dtypes: float64(4), int64(7), object(5)
memory usage: 2.6+ MB
Also, for an ancillary geography, we will use the neighbourhoods provided by the same source:
url = (
"http://data.insideairbnb.com/china/beijing/beijing/"
"2023-03-29/visualisations/neighbourhoods.geojson"
)
url
'http://data.insideairbnb.com/china/beijing/beijing/2023-03-29/visualisations/neighbourhoods.geojson'
neis = geopandas.read_file(url)
Alternative
Instead of reading the file directly off the web, it is possible to download it manually, store it on your computer, and read it locally. To do that, you can follow these steps:
Download the file by right-clicking on this link and saving the file
Place the file on the same folder as the notebook where you intend to read it
Replace the code in the cell above by:
neis = geopandas.read_file("neighbourhoods.geojson")
Note the code cell above requires internet connectivity. If you are not online but have a full copy of the GDS course in your computer (downloaded as suggested in the infrastructure page), you can read the data with the following line of code:
neis = geopandas.read_file("../data/web_cache/abb_neis.gpkg")
neis.info()
<class 'geopandas.geodataframe.GeoDataFrame'>
RangeIndex: 16 entries, 0 to 15
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 neighbourhood 16 non-null object
1 neighbourhood_group 0 non-null object
2 geometry 16 non-null geometry
dtypes: geometry(1), object(2)
memory usage: 512.0+ bytes
With these at hand, get to work with the following challenges:
Create a Hex binning map of the property locations
Compute and display a kernel density estimate (KDE) of the distribution of the properties
Using the neighbourhood layer:
Obtain a count of property by neighbourhood (nothe the neighbourhood name is present in the property table and you can connect the two tables through that)
Create a raw count choropleth
Create a choropleth of the density of properties by polygon
Task II: Clusters of Indian cities#
For this one, we are going to use a dataset on the location of populated places in India provided by http://geojson.xyz. The original table covers the entire world so, to get it ready for you to work on it, we need to prepare it:
url = (
"https://d2ad6b4ur7yvpq.cloudfront.net/naturalearth-3.3.0/"
"ne_50m_populated_places_simple.geojson"
)
url
'https://d2ad6b4ur7yvpq.cloudfront.net/naturalearth-3.3.0/ne_50m_populated_places_simple.geojson'
Let’s read the file in and keep only places from India:
places = geopandas.read_file(url).query("adm0name == 'India'")
Alternative
Instead of reading the file directly off the web, it is possible to download it manually, store it on your computer, and read it locally. To do that, you can follow these steps:
Download the file by right-clicking on this link and saving the file
Place the file on the same folder as the notebook where you intend to read it
Replace the code in the cell above by:
places = geopandas.read_file("ne_50m_populated_places_simple.geojson")
Note the code cell above requires internet connectivity. If you are not online but have a full copy of the GDS course in your computer (downloaded as suggested in the infrastructure page), you can read the data with the following line of code:
places = geopandas.read_file(
"../data/web_cache/places.gpkg"
).query("adm0name == 'India'")
By defaul, place locations come expressed in longitude and latitude. Because you will be working with distances, it makes sense to convert the table into a system expressed in metres. For India, this can be the “Kalianpur 1975 / India zone I” (EPSG:24378) projection.
places_m = places.to_crs(epsg=24378)
This is what we have to work with then:
ax = places_m.plot(
color="xkcd:bright yellow", figsize=(9, 9)
)
contextily.add_basemap(
ax,
crs=places_m.crs,
source=contextily.providers.CartoDB.DarkMatter
)
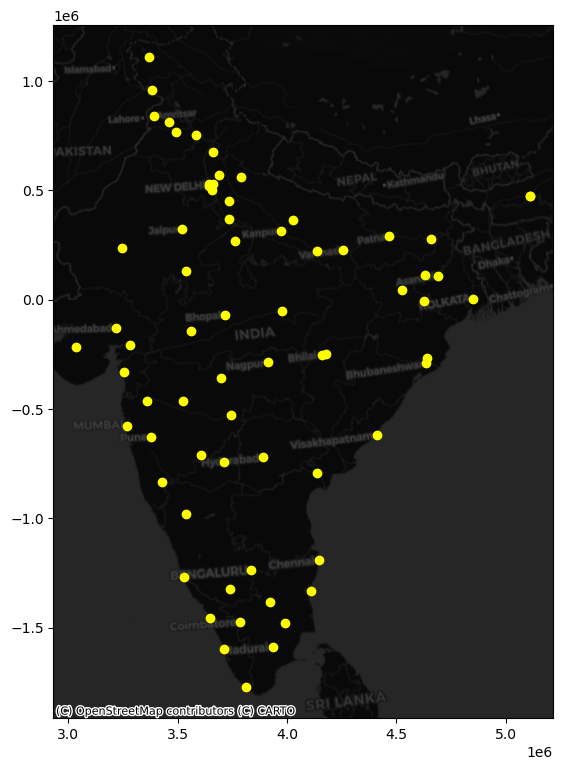
With this at hand, get to work:
Use the DBSCAN algorithm to identify clusters
Start with the following parameters: at least five cities for a cluster (
min_samples) and a maximum of 1,000Km (eps)Obtain the clusters and plot them on a map. Does it pick up any interesting pattern?
Based on the results above, tweak the values of both parameters to find a cluster of southern cities, and another one of cities in the North around New Dehli