Hands-on#
Spatial weights#
In this session we will be learning the ins and outs of one of the key pieces in spatial analysis: spatial weights matrices. These are structured sets of numbers that formalize geographical relationships between the observations in a dataset. Essentially, a spatial weights matrix of a given geography is a positive definite matrix of dimensions \(N\) by \(N\), where \(N\) is the total number of observations:
where each cell \(w_{ij}\) contains a value that represents the degree of spatial contact or interaction between observations \(i\) and \(j\). A fundamental concept in this context is that of neighbor and neighborhood. By convention, elements in the diagonal (\(w_{ii}\)) are set to zero. A neighbor of a given observation \(i\) is another observation with which \(i\) has some degree of connection. In terms of \(W\), \(i\) and \(j\) are thus neighbors if \(w_{ij} > 0\). Following this logic, the neighborhood of \(i\) will be the set of observations in the system with which it has certain connection, or those observations with a weight greater than zero.
There are several ways to create such matrices, and many more to transform them so they contain an accurate representation that aligns with the way we understand spatial interactions between the elements of a system. In this session, we will introduce the most commonly used ones and will show how to compute them with PySAL.
%matplotlib inline
import seaborn as sns
import pandas as pd
from pysal.lib import weights
from libpysal.io import open as psopen
import geopandas as gpd
import numpy as np
import matplotlib.pyplot as plt
Data#
For this tutorial, we will use a dataset of Liverpool small areas (or Lower layer Super Output Areas, LSOAs) for Liverpool. The table is available as part of this course, so can be accessed remotely through the web. If you want to see how the table was created, a notebook is available here.
To make things easier, we will read data from a file posted online so, for now, you do not need to download any dataset:
# Read the file in
db = gpd.read_file(
"https://darribas.org/gds_course/content/data/liv_lsoas.gpkg"
)
# Index table on the LSOA ID
db = db.set_index("LSOA11CD", drop=False)
# Display summary
db.info()
<class 'geopandas.geodataframe.GeoDataFrame'>
Index: 298 entries, E01006512 to E01033768
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 LSOA11CD 298 non-null object
1 MSOA11CD 298 non-null object
2 geometry 298 non-null geometry
dtypes: geometry(1), object(2)
memory usage: 9.3+ KB
/opt/conda/lib/python3.8/site-packages/geopandas/geodataframe.py:577: RuntimeWarning: Sequential read of iterator was interrupted. Resetting iterator. This can negatively impact the performance.
for feature in features_lst:
Alternative
Instead of reading the file directly off the web, it is possible to download it manually, store it on your computer, and read it locally. To do that, you can follow these steps:
Download the file by right-clicking on this link and saving the file
Place the file on the same folder as the notebook where you intend to read it
Replace the code in the cell above by:
db = gpd.read_file("liv_lsoas.gpkg")
Building spatial weights in PySAL#
Contiguity#
Contiguity weights matrices define spatial connections through the existence of common boundaries. This makes it directly suitable to use with polygons: if two polygons share boundaries to some degree, they will be labeled as neighbors under these kinds of weights. Exactly how much they need to share is what differenciates the two approaches we will learn: queen and rook.
Queen
Under the queen criteria, two observations only need to share a vortex (a single point) of their boundaries to be considered neighbors. Constructing a weights matrix under these principles can be done by running:
w_queen = weights.Queen.from_dataframe(db, idVariable="LSOA11CD")
w_queen
<libpysal.weights.contiguity.Queen at 0x7fba3879f910>
The command above creates an object w_queen of the class W. This is the format in which spatial weights matrices are stored in PySAL. By default, the weights builder (Queen.from_dataframe) will use the index of the table, which is useful so we can keep everything in line easily.
A W object can be queried to find out about the contiguity relations it contains. For example, if we would like to know who is a neighbor of observation E01006690:
w_queen['E01006690']
{'E01006697': 1.0,
'E01006692': 1.0,
'E01033763': 1.0,
'E01006759': 1.0,
'E01006695': 1.0,
'E01006720': 1.0,
'E01006691': 1.0}
This returns a Python dictionary that contains the ID codes of each neighbor as keys, and the weights they are assigned as values. Since we are looking at a raw queen contiguity matrix, every neighbor gets a weight of one. If we want to access the weight of a specific neighbor, E01006691 for example, we can do recursive querying:
w_queen['E01006690']['E01006691']
1.0
W objects also have a direct way to provide a list of all the neighbors or their weights for a given observation. This is thanks to the neighbors and weights attributes:
w_queen.neighbors['E01006690']
['E01006697',
'E01006692',
'E01033763',
'E01006759',
'E01006695',
'E01006720',
'E01006691']
w_queen.weights['E01006690']
[1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0]
Once created, W objects can provide much information about the matrix, beyond the basic attributes one would expect. We have direct access to the number of neighbors each observation has via the attribute cardinalities. For example, to find out how many neighbors observation E01006524 has:
w_queen.cardinalities['E01006524']
6
Since cardinalities is a dictionary, it is direct to convert it into a Series object:
queen_card = pd.Series(w_queen.cardinalities)
queen_card.head()
E01006512 6
E01006513 9
E01006514 5
E01006515 8
E01006518 5
dtype: int64
This allows, for example, to access quick plotting, which comes in very handy to get an overview of the size of neighborhoods in general:
sns.distplot(queen_card, bins=10)
/opt/conda/lib/python3.8/site-packages/seaborn/distributions.py:2557: FutureWarning: `distplot` is a deprecated function and will be removed in a future version. Please adapt your code to use either `displot` (a figure-level function with similar flexibility) or `histplot` (an axes-level function for histograms).
warnings.warn(msg, FutureWarning)
<AxesSubplot:ylabel='Density'>
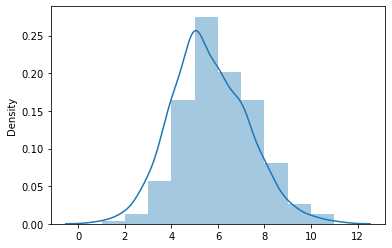
The figure above shows how most observations have around five neighbors, but there is some variation around it. The distribution also seems to follow a symmetric form, where deviations from the average occur both in higher and lower values almost evenly.
Some additional information about the spatial relationships contained in the matrix are also easily available from a W object. Let us tour over some of them:
# Number of observations
w_queen.n
298
# Average number of neighbors
w_queen.mean_neighbors
5.617449664429531
# Min number of neighbors
w_queen.min_neighbors
1
# Max number of neighbors
w_queen.max_neighbors
11
# Islands (observations disconnected)
w_queen.islands
[]
# Order of IDs (first five only in this case)
w_queen.id_order[:5]
['E01006512', 'E01006513', 'E01006514', 'E01006515', 'E01006518']
Spatial weight matrices can be explored visually in other ways. For example, we can pick an observation and visualize it in the context of its neighborhood. The following plot does exactly that by zooming into the surroundings of LSOA E01006690 and displaying its polygon as well as those of its neighbors:
# Setup figure
f, ax = plt.subplots(1, figsize=(6, 6))
# Plot base layer of polygons
db.plot(ax=ax, facecolor='k', linewidth=0.1)
# Select focal polygon
# NOTE we pass both the area code and the column name
# (`geometry`) within brackets!!!
focus = db.loc[['E01006690'], ['geometry']]
# Plot focal polygon
focus.plot(facecolor='red', alpha=1, linewidth=0, ax=ax)
# Plot neighbors
neis = db.loc[w_queen['E01006690'], :]
neis.plot(ax=ax, facecolor='lime', linewidth=0)
# Title
f.suptitle("Queen neighbors of `E01006690`")
# Style and display on screen
ax.set_ylim(388000, 393500)
ax.set_xlim(336000, 339500)
plt.show()
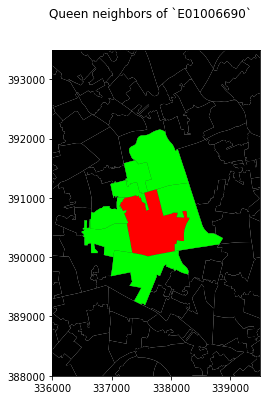
Note how the figure is built gradually, from the base map (L. 4-5), to the focal point (L. 9), to its neighborhood (L. 11-13). Once the entire figure is plotted, we zoom into the area of interest (L. 19-20).
Rook
Rook contiguity is similar to and, in many ways, superseded by queen contiguity. However, since it sometimes comes up in the literature, it is useful to know about it. The main idea is the same: two observations are neighbors if they share some of their boundary lines. However, in the rook case, it is not enough with sharing only one point, it needs to be at least a segment of their boundary. In most applied cases, these differences usually boil down to how the geocoding was done, but in some cases, such as when we use raster data or grids, this approach can differ more substantively and it thus makes more sense.
From a technical point of view, constructing a rook matrix is very similar:
w_rook = weights.Rook.from_dataframe(db)
w_rook
<libpysal.weights.contiguity.Rook at 0x7fba38676df0>
The output is of the same type as before, a W object that can be queried and used in very much the same way as any other one.
Distance#
Distance based matrices assign the weight to each pair of observations as a function of how far from each other they are. How this is translated into an actual weight varies across types and variants, but they all share that the ultimate reason why two observations are assigned some weight is due to the distance between them.
K-Nearest Neighbors
One approach to define weights is to take the distances between a given observation and the rest of the set, rank them, and consider as neighbors the \(k\) closest ones. That is exactly what the \(k\)-nearest neighbors (KNN) criterium does.
To calculate KNN weights, we can use a similar function as before and derive them from a shapefile:
knn5 = weights.KNN.from_dataframe(db, k=5)
knn5
<libpysal.weights.distance.KNN at 0x7fba34e3dfd0>
Note how we need to specify the number of nearest neighbors we want to consider with the argument k. Since it is a polygon shapefile that we are passing, the function will automatically compute the centroids to derive distances between observations. Alternatively, we can provide the points in the form of an array, skipping this way the dependency of a file on disk:
# Extract centroids
cents = db.centroid
# Extract coordinates into an array
pts = pd.DataFrame(
{"X": cents.x, "Y": cents.y}
).values
# Compute KNN weights
knn5_from_pts = weights.KNN.from_array(pts, k=5)
knn5_from_pts
<libpysal.weights.distance.KNN at 0x7fba386707f0>
Distance band
Another approach to build distance-based spatial weights matrices is to draw a circle of certain radious and consider neighbor every observation that falls within the circle. The technique has two main variations: binary and continuous. In the former one, every neighbor is given a weight of one, while in the second one, the weights can be further tweaked by the distance to the observation of interest.
To compute binary distance matrices in PySAL, we can use the following command:
w_dist1kmB = weights.DistanceBand.from_dataframe(db, 1000)
/opt/conda/lib/python3.8/site-packages/libpysal/weights/weights.py:172: UserWarning: The weights matrix is not fully connected:
There are 2 disconnected components.
warnings.warn(message)
This creates a binary matrix that considers neighbors of an observation every polygon whose centroid is closer than 1,000 metres (1Km) of the centroid of such observation. Check, for example, the neighborhood of polygon E01006690:
w_dist1kmB['E01006690']
{'E01006691': 1.0,
'E01006692': 1.0,
'E01006695': 1.0,
'E01006697': 1.0,
'E01006720': 1.0,
'E01006725': 1.0,
'E01006726': 1.0,
'E01033763': 1.0}
Note that the units in which you specify the distance directly depend on the CRS in which the spatial data are projected, and this has nothing to do with the weights building but it can affect it significantly. Recall how you can check the CRS of a GeoDataFrame:
db.crs
<Projected CRS: PROJCS["Transverse_Mercator",GEOGCS["GCS_OSGB 1936 ...>
Name: Transverse_Mercator
Axis Info [cartesian]:
- [east]: Easting (metre)
- [north]: Northing (metre)
Area of Use:
- undefined
Coordinate Operation:
- name: unnamed
- method: Transverse Mercator
Datum: OSGB 1936
- Ellipsoid: Airy 1830
- Prime Meridian: Greenwich
In this case, you can see the unit is expressed in metres (m), hence we set the threshold to 1,000 for a circle of 1km of radious.
An extension of the weights above is to introduce further detail by assigning different weights to different neighbors within the radious circle based on how far they are from the observation of interest. For example, we could think of assigning the inverse of the distance between observations \(i\) and \(j\) as \(w_{ij}\). This can be computed with the following command:
w_dist1kmC = weights.DistanceBand.from_dataframe(db, 1000, binary=False)
/opt/conda/lib/python3.8/site-packages/scipy/sparse/data.py:117: RuntimeWarning: divide by zero encountered in reciprocal
return self._with_data(data ** n)
In w_dist1kmC, every observation within the 1km circle is assigned a weight equal to the inverse distance between the two:
This way, the further apart \(i\) and \(j\) are from each other, the smaller the weight \(w_{ij}\) will be.
Contrast the binary neighborhood with the continuous one for E01006690:
w_dist1kmC['E01006690']
{'E01006691': 0.001320115452290246,
'E01006692': 0.0016898106255168294,
'E01006695': 0.001120923796462639,
'E01006697': 0.001403469553911711,
'E01006720': 0.0013390451319917913,
'E01006725': 0.001009044334260805,
'E01006726': 0.0010528395831202145,
'E01033763': 0.0012983249272553688}
Following this logic of more detailed weights through distance, there is a temptation to take it further and consider everyone else in the dataset as a neighbor whose weight will then get modulated by the distance effect shown above. However, although conceptually correct, this approach is not always the most computationally or practical one. Because of the nature of spatial weights matrices, particularly because of the fact their size is \(N\) by \(N\), they can grow substantially large. A way to cope with this problem is by making sure they remain fairly sparse (with many zeros). Sparsity is typically ensured in the case of contiguity or KNN by construction but, with inverse distance, it needs to be imposed as, otherwise, the matrix could be potentially entirely dense (no zero values other than the diagonal). In practical terms, what is usually done is to impose a distance threshold beyond which no weight is assigned and interaction is assumed to be non-existent. Beyond being computationally feasible and scalable, results from this approach usually do not differ much from a fully “dense” one as the additional information that is included from further observations is almost ignored due to the small weight they receive. In this context, a commonly used threshold, although not always best, is that which makes every observation to have at least one neighbor.
Such a threshold can be calculated as follows:
min_thr = weights.min_threshold_distance(pts)
min_thr
939.7373992113434
Which can then be used to calculate an inverse distance weights matrix:
w_min_dist = weights.DistanceBand.from_dataframe(db, min_thr, binary=False)
Block weights#
Block weights connect every observation in a dataset that belongs to the same category in a list provided ex-ante. Usually, this list will have some relation to geography an the location of the observations but, technically speaking, all one needs to create block weights is a list of memberships. In this class of weights, neighboring observations, those in the same group, are assigned a weight of one, and the rest receive a weight of zero.
In this example, we will build a spatial weights matrix that connects every LSOA with all the other ones in the same MSOA. See how the MSOA code is expressed for every LSOA:
db.head()
| LSOA11CD | MSOA11CD | geometry | |
|---|---|---|---|
| LSOA11CD | |||
| E01006512 | E01006512 | E02001377 | POLYGON ((336103.358 389628.580, 336103.416 38... |
| E01006513 | E01006513 | E02006932 | POLYGON ((335173.781 389691.538, 335169.798 38... |
| E01006514 | E01006514 | E02001383 | POLYGON ((335495.676 389697.267, 335495.444 38... |
| E01006515 | E01006515 | E02001383 | POLYGON ((334953.001 389029.000, 334951.000 38... |
| E01006518 | E01006518 | E02001390 | POLYGON ((335354.015 388601.947, 335354.000 38... |
To build a block spatial weights matrix that connects as neighbors all the LSOAs in the same MSOA, we only require the mapping of codes. Using PySAL, this is a one-line task:
w_block = weights.block_weights(db['MSOA11CD'])
/opt/conda/lib/python3.8/site-packages/libpysal/weights/weights.py:172: UserWarning: The weights matrix is not fully connected:
There are 61 disconnected components.
warnings.warn(message)
In this case, PySAL does not allow to pass the argument idVariable as above. As a result, observations are named after the order the occupy in the list:
w_block[0]
{218: 1.0, 219: 1.0, 220: 1.0, 292: 1.0}
The first element is neighbor of observations 218, 129, 220, and 292, all of them with an assigned weight of 1. However, it is possible to correct this by using the additional method remap_ids:
w_block.remap_ids(db.index)
Now if you try w_bloc[0], it will return an error. But if you query for the neighbors of an observation by its LSOA id, it will work:
w_block['E01006512']
{'E01006747': 1.0, 'E01006748': 1.0, 'E01006751': 1.0, 'E01033763': 1.0}
Standardizing W matrices#
In the context of many spatial analysis techniques, a spatial weights matrix with raw values (e.g. ones and zeros for the binary case) is not always the best suiting one for analysis and some sort of transformation is required. This implies modifying each weight so they conform to certain rules. PySAL has transformations baked right into the W object, so it is possible to check the state of an object as well as to modify it.
Consider the original queen weights, for observation E01006690:
w_queen['E01006690']
{'E01006697': 1.0,
'E01006692': 1.0,
'E01033763': 1.0,
'E01006759': 1.0,
'E01006695': 1.0,
'E01006720': 1.0,
'E01006691': 1.0}
Since it is contiguity, every neighbor gets one, the rest zero weight. We can check if the object w_queen has been transformed or not by calling the argument transform:
w_queen.transform
'O'
where O stands for “original”, so no transformations have been applied yet. If we want to apply a row-based transformation, so every row of the matrix sums up to one, we modify the transform attribute as follows:
w_queen.transform = 'R'
Now we can check the weights of the same observation as above and find they have been modified:
w_queen['E01006690']
{'E01006697': 0.14285714285714285,
'E01006692': 0.14285714285714285,
'E01033763': 0.14285714285714285,
'E01006759': 0.14285714285714285,
'E01006695': 0.14285714285714285,
'E01006720': 0.14285714285714285,
'E01006691': 0.14285714285714285}
Save for precission issues, the sum of weights for all the neighbors is one:
pd.Series(w_queen['E01006690']).sum()
0.9999999999999998
Returning the object back to its original state involves assigning transform back to original:
w_queen.transform = 'O'
w_queen['E01006690']
{'E01006697': 1.0,
'E01006692': 1.0,
'E01033763': 1.0,
'E01006759': 1.0,
'E01006695': 1.0,
'E01006720': 1.0,
'E01006691': 1.0}
PySAL supports the following transformations:
O: original, returning the object to the initial state.B: binary, with every neighbor having assigned a weight of one.R: row, with all the neighbors of a given observation adding up to one.V: variance stabilizing, with the sum of all the weights being constrained to the number of observations.
Reading and Writing spatial weights in PySAL#
Sometimes, if a dataset is very detailed or large, it can be costly to build the spatial weights matrix of a given geography and, despite the optimizations in the PySAL code, the computation time can quickly grow out of hand. In these contexts, it is useful to not have to re-build a matrix from scratch every time we need to re-run the analysis. A useful solution in this case is to build the matrix once, and save it to a file where it can be reloaded at a later stage if needed.
PySAL has a common way to write any kind of W object into a file using the command open. The only element we need to decide for ourselves beforehand is the format of the file. Although there are several formats in which spatial weight matrices can be stored, we will focused on the two most commonly used ones:
.galfiles for contiguity weights
Contiguity spatial weights can be saved into a .gal file with the following commands:
# Open file to write into
fo = psopen('imd_queen.gal', 'w')
# Write the matrix into the file
fo.write(w_queen)
# Close the file
fo.close()
The process is composed by the following three steps:
Open a target file for
writing the matrix, hence thewargument. In this case, if a fileimd_queen.galalready exists, it will be overwritten, so be careful.Write the
Wobject into the file.Close the file. This is important as some additional information is written into the file at this stage, so failing to close the file might have unintended consequences.
Once we have the file written, it is possible to read it back into memory with the following command:
w_queen2 = psopen('imd_queen.gal', 'r').read()
w_queen2
<libpysal.weights.weights.W at 0x7fba351d76a0>
Note how we now use r instead of w because we are reading the file, and also notice how we open the file and, in the same line, we call read() directly.
.gwtfiles for distance-based weights.
A very similar process to the one above can be used to read and write distance based weights. The only difference is specifying the right file format, .gwt in this case. So, if we want to write w_dist1km into a file, we will run:
# Open file
fo = psopen('imd_dist1km.gwt', 'w')
# Write matrix into the file
fo.write(w_dist1kmC)
# Close file
fo.close()
And if we want to read the file back in, all we need to do is:
w_dist1km2 = psopen('imd_dist1km.gwt', 'r').read()
/opt/conda/lib/python3.8/site-packages/libpysal/io/iohandlers/gwt.py:204: RuntimeWarning: DBF relating to GWT was not found, proceeding with unordered string IDs.
warn(msg, RuntimeWarning)
/opt/conda/lib/python3.8/site-packages/libpysal/weights/weights.py:172: UserWarning: The weights matrix is not fully connected:
There are 2 disconnected components.
warnings.warn(message)
Note how, in this case, you will probably receive a warning alerting you that there was not a DBF relating to the file. This is because, by default, PySAL takes the order of the observations in a .gwt from a shapefile. If this is not provided, PySAL cannot entirely determine all the elements and hence the resulting W might not be complete (islands, for example, can be missing). To fully complete the reading of the file, we can remap the ids as we have seen above:
w_dist1km2.remap_ids(db.index)
Spatial Lag#
One of the most direct applications of spatial weight matrices is the so-called spatial lag. The spatial lag of a given variable is the product of a spatial weight matrix and the variable itself:
where \(Y\) is a Nx1 vector with the values of the variable. Recall that the product of a matrix and a vector equals the sum of a row by column element multiplication for the resulting value of a given row. In terms of the spatial lag:
If we are using row-standardized weights, \(w_{ij}\) becomes a proportion between zero and one, and \(y_{sl-i}\) can be seen as the average value of \(Y\) in the neighborhood of \(i\).
For this illustration, we will use the area of each polygon as the variable of interest. And to make things a bit nicer later on, we will keep the log of the area instead of the raw measurement. Hence, let’s create a column for it:
db["area"] = np.log(db.area)
The spatial lag is a key element of many spatial analysis techniques, as we will see later on and, as such, it is fully supported in PySAL. To compute the spatial lag of a given variable, area for example:
# Row-standardize the queen matrix
w_queen.transform = 'R'
# Compute spatial lag of `area`
w_queen_score = weights.lag_spatial(w_queen, db["area"])
# Print the first five elements
w_queen_score[:5]
array([12.40660189, 12.54225296, 12.28284814, 12.61675295, 12.55042815])
Line 4 contains the actual computation, which is highly optimized in PySAL. Note that, despite passing in a pd.Series object, the output is a numpy array. This however, can be added directly to the table db:
db['w_area'] = w_queen_score
Moran Plot#
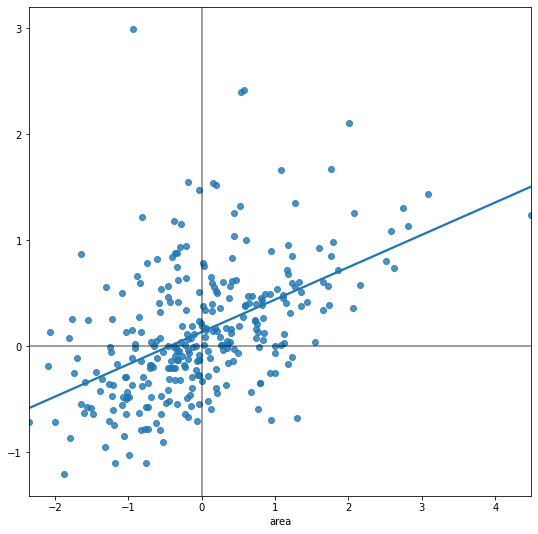
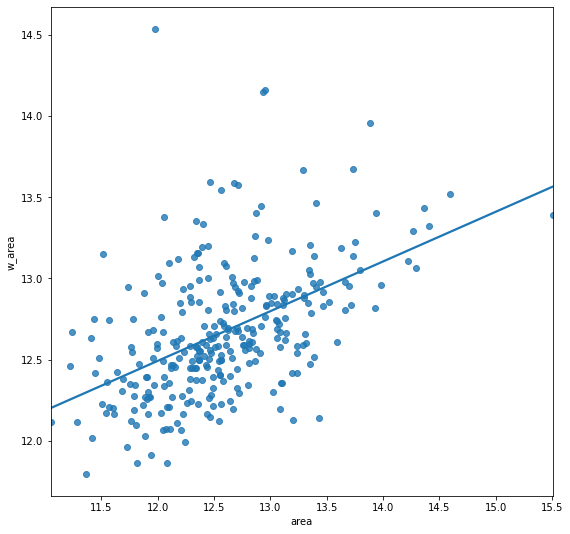
The Moran Plot is a graphical way to start exploring the concept of spatial autocorrelation, and it is a good application of spatial weight matrices and the spatial lag. In essence, it is a standard scatter plot in which a given variable (area, for example) is plotted against its own spatial lag. Usually, a fitted line is added to include more information:
# Setup the figure and axis
f, ax = plt.subplots(1, figsize=(9, 9))
# Plot values
sns.regplot(x="area", y="w_area", data=db, ci=None)
# Display
plt.show()
In order to easily compare different scatter plots and spot outlier observations, it is common practice to standardize the values of the variable before computing its spatial lag and plotting it. This can be accomplished by substracting the average value and dividing the result by the standard deviation:
where \(z_i\) is the standardized version of \(y_i\), \(\bar{y}\) is the average of the variable, and \(\sigma\) its standard deviation.
Creating a standardized Moran Plot implies that average values are centered in the plot (as they are zero when standardized) and dispersion is expressed in standard deviations, with the rule of thumb of values greater or smaller than two standard deviations being outliers. A standardized Moran Plot also partitions the space into four quadrants that represent different situations:
High-High (HH): values above average surrounded by values above average.
Low-Low (LL): values below average surrounded by values below average.
High-Low (HL): values above average surrounded by values below average.
Low-High (LH): values below average surrounded by values above average.
These will be further explored once spatial autocorrelation has been properly introduced in subsequent blocks.
# Standardize the area
std_db = (db['area'] - db['area'].mean()) / db['area'].std()
# Compute the spatial lag of the standardized version and save is as a
# Series indexed as the original variable
std_w_db = pd.Series(
weights.lag_spatial(w_queen, std_db), index=std_db.index
)
# Setup the figure and axis
f, ax = plt.subplots(1, figsize=(9, 9))
# Plot values
sns.regplot(x=std_db, y=std_w_db, ci=None)
# Add vertical and horizontal lines
plt.axvline(0, c='k', alpha=0.5)
plt.axhline(0, c='k', alpha=0.5)
# Display
plt.show()