Geographic Data Science
Non-spatial clustering
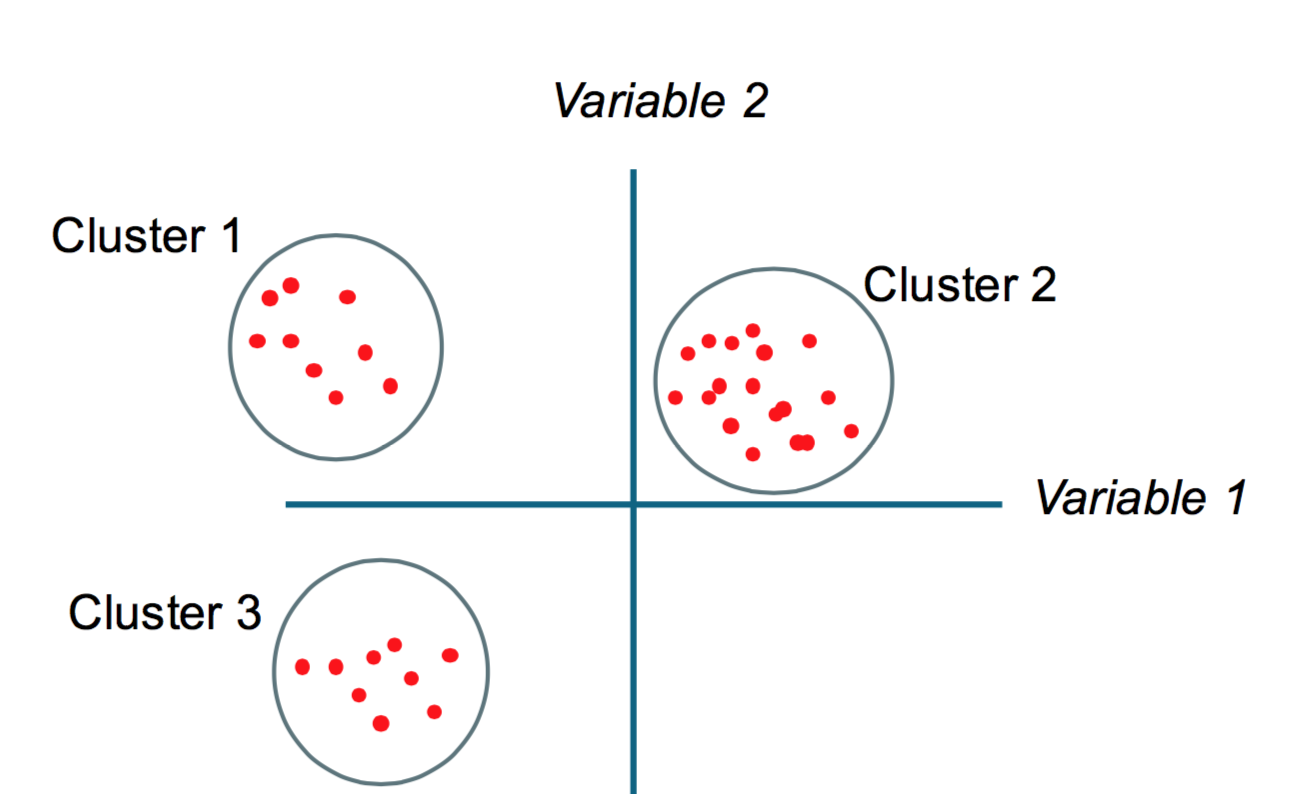
Split a dataset into groups of observations that are similar within the group and dissimilar between groups, based on a series of attributes
Machine learning
The computer learns some of the properties of the dataset without the human specifying them
Unsupervised
There is no a-priori structure imposed on the classification → before the analysis, no observations is in a category
Intuition
K-means
- Most popular clustering algorithm
- Good but not perfect
- Watch video for int
More clustering…
- Hierarchical clustering
- Agglomerative clustering
- Spectral clustering
- Neural networks (e.g. Self-Organizing Maps)
- DBSCAN
- …
Different properties, different best usecases
See interesting comparison table
Geodemographic analysis
Geodemographic analysis
|

|

A course on Geographic Data Science by Dani Arribas-Bel is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.